Oracle GDSの時代がやって来た!
この記事は JPOUG Advent Calendar 2020 13日目の記事です。 12日目は 明治そして大正昭和平成令和さん の記事『OCIといえばOracle Call Interface』でした。
はじめに
エンタープライズ基盤のDBでは、Oracle DBが最強!という主張にほとんど異論はないと思っていますが、パブリッククラウドのDBでは、クラウドの特性上、複数のリージョンやゾーンにDBインスタンスを分散配置してアベイラビリティとスケーラビリティを実現するDBアーキテクチャが主流になっていることや、OCI(Oracle Cloud Infrastructure)以外ではRACが構成できないことなどもあってか、残念ながらOracle DBを採用した構成をほとんど聞くことがありません。
個人的には、パブリッククラウドでOracle DBがもっと使われるようにするための解決策の一つは、パブリッククラウドと親和性の高いDBアーキテクチャを実装できるようにすること、具体的には、複数のリージョンやゾーンにDBインスタンスを分散配置してアベイラビリティとスケーラビリティを簡単に実装できるようにすることだと考えていますが、それに最適な機能がOracle DB 12c Enterprise Editionから導入されたOracle GDS(Global Data Services)です。
現時点では、Oracle GDSは国内での導入実績がおそらくないと思われるのですが(あったら教えて下さい!)、やっと時代が機能に追いついて来た感があります。
というわけで、この記事ではOracle GDSについて紹介します。

Oracle GDSの概要
Oracle DBには、DBレプリケーションを実現する機能や製品として、Active Data Guard(物理レプリケーション)やGoldenGate(論理レプリケーション)がありますが、これらの機能や製品を用いて異なるリージョンやゾーンに複数のDBレプリカを構築した場合、DBレプリカ・ファームへのクライアント接続のロード・バランシングが課題になります。
RACでは、DBインスタンス間での動的なワークロード管理機能のサービス(ローカル・サービス)がありますが、そのサービスの概念を地理的に分散配置された単一インスタンス、RAC、Active Data Guard、GoldenGateの任意の組み合わせのDBインスタンス(DBレプリカ)にまで拡張してグローバル・サービスとしてワークロード管理機能を提供できるようにしたものがGDSになります。
GDSでは、地理的な配置(リージョン)やレプリケーションの遅延(Active Data Guardのみ)などを考慮したDBインスタンスのワークロード管理のため、ローカル・サービスにはないグローバル・サービス固有の以下の3つの属性を追加しています。
- 優先または使用可能なデータベース
- レプリケーション・ラグ
- リージョン・アフィニティ
これにより、リージョンやラグを考慮した複数DBインスタンスへのロード・バランシングやフェイル・オーバーがグローバル・サービスによって可能になります。
GDSのアーキテクチャ
GDSのアーキテクチャを構成するコンポーネントと概要は以下の通りです。
- GSM(Global Service Manager)
- GDSカタログ
- GDSとGDSが提供するすべてのグローバル・サービスに関するコンフィグレーション・データを格納するためのリポジトリです。
- GDSリージョン
- ネットワーク的に近接しているDBとクライアントのサブセットです。一つのGDSリージョンには複数のGDSプールを含めることができます。
- GDSプール
- 一意のグローバル・サービスを提供するDBのサブセットです。DBは一つのGDSプールにのみ所属できます。また、GDSプールは複数のGDSリージョンに跨がることができます。
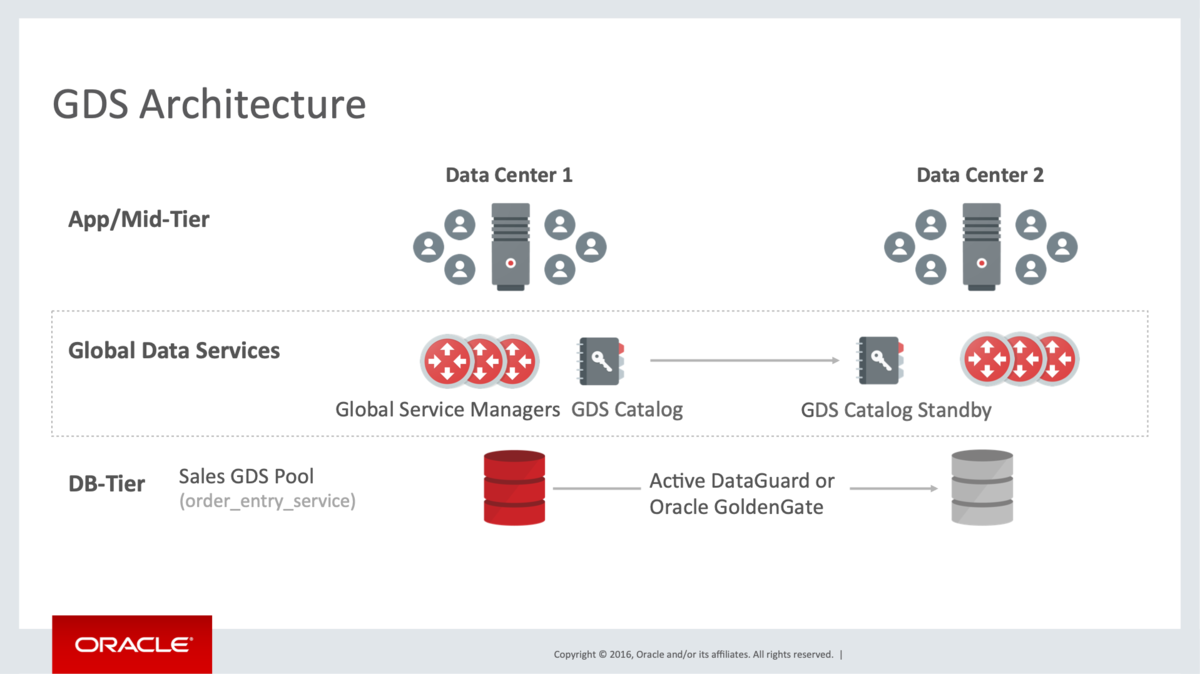
GDSでは、GDSリージョンごとに複数のGSM サーバー(3サーバ以上)を構成することが推奨されており、各リージョンにある一つのGSMがマスターになります。 また、GDSカタログのDBもData Guardによる冗長化構成が推奨されています。
GDSのユースケース
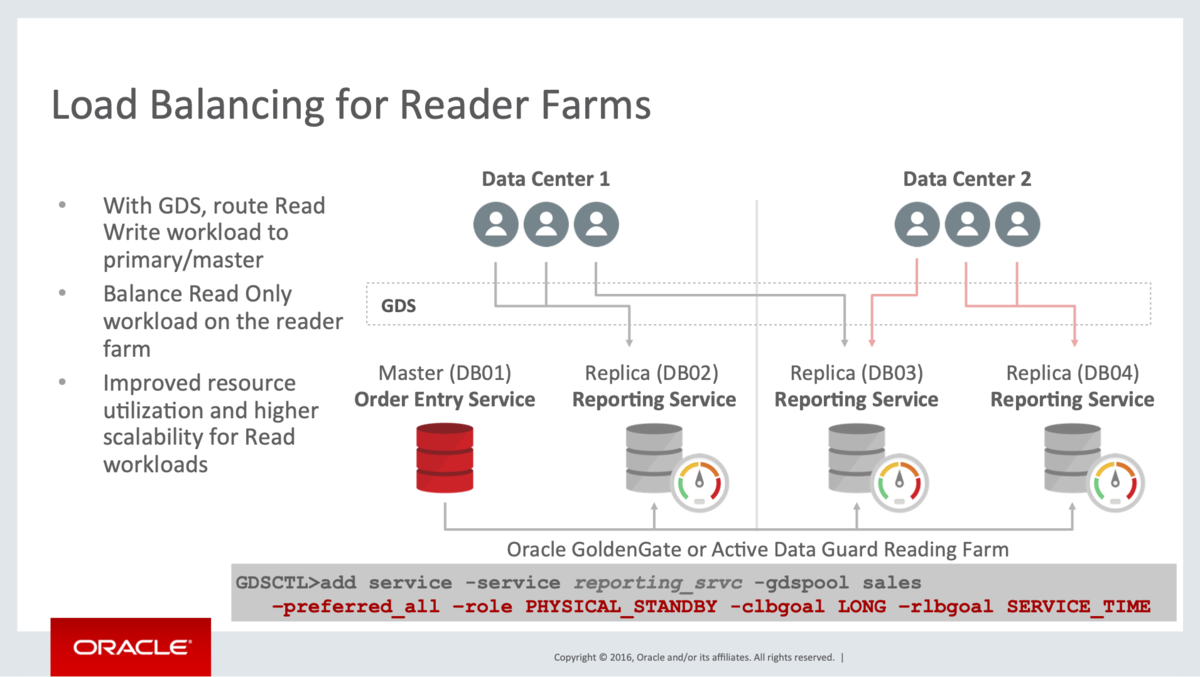
GDSのユースケースは多岐に渡ると思いますが、記事の冒頭に書いたように地理的に分散配置されたDBレプリカ・ファームへのロード・バランシングが一番のユースケースだと思います。
以下の図のように異なるリージョンに配置されたマスターDBとリードレプリカDB・ファームがあった場合、GDSでは、Read/WriteのワークロードはマスターDBへ、Read Onlyのワークロードはパフォーマンスやネットワークの状況(負荷や遅延)、優先度などに応じた適切なレプリカDBへとルーティングしてくれます。
最後に
この記事を読んで、少しでもGDSに興味を持ってもらえるとうれしいです。
私自身でがまだGDSの構築や動作検証は実施していないので、テクニカルに間違いなどあればぜひご指摘ください。
来年は時間を作ってGDSの検証したいです!
リファレンス
データベースパフォーマンスチューニングのための10の秘訣
先日公開された以下の記事がデータベースのパフォーマンスチューニングについて非常に示唆に富む内容だったので、新型コロナで持て余した時間を使って、個人的な趣味でざっくり意訳してみました!
誤訳や日本語として変なところが多々あるかと思いますので適宜修正していきますが、正しい内容は原文を参照してくださいねー。
基本的にOracleデータベースやExadataに関する内容となっていますが、データベースパフォーマンスチューニングのための10の秘訣(チップス)です。
1. パフォーマンス測定の主要なアプリケーションのメトリックを特定する
パフォーマンスを測定するときは、アプリケーションの稼働状況を反映したりエンドユーザーの体感を代理するような主要なアプリケーションのメトリックを特定します。このメトリックはデータベース外部のものであるべきです。例えば、秒間のオーダー処理数やバッチジョブの経過時間などです。アプリケーションレベルのメトリックを持つことでパフォーマンスが重要な箇所が改善されているかどうかを客観的に測定することができます。
主要なメトリックに基づいた判定基準を定義します。これにより進捗状況を測定することで停止できるタイミングを知ることができます。ときには変更を継続したいと思うかもしれませんがすでに目標を達成していて変更が重大な影響を与えないのであれば停止してください。
主要なメトリックはひとつだけにすべきです。もしたくさんのメトリックを持っていた場合、いくつかのメトリックは改善してもほかのメトリックが悪くなるかもしれませんのできちんとパフォーマンスの変更を評価することができなくなります。もし複数のメトリックを測定しないといけない場合、お互いが完全に独立していて個別に評価することができる方法で測定します。
2. パフォーマンスの問題を定義してその範囲を把握する
パフォーマンス問題の明確な定義(具体的に何が遅くてどれくらい遅いのか?)を持つことは必要かつ重要です。
パフォーマンス問題の定義の一部としてその範囲を把握することについてもです(クエリーのセットやユーザのセットは限定されているか?、もっと広範囲でデータベースインスタンス、もしかしたら複数データベースの全ユーザに影響するか?)。問題の範囲を把握することにより、問題の範囲に一致する診断データを使用することができます。もし問題が少数のユーザのみに限定されている場合、システム全体の統計を使用することは関係ないかもしれません。
同じようにほかのソリューションの場合にも問題の範囲には一致させるべきです(例えば、問題が少数のクエリーやユーザーに限定されている場合、ソリューションはこれらユーザー/クエリーにのみ集中すべきで、システムの全ユーザにネガティブな影響を与える可能性のある初期化パラメータなどを変更してはいけません)
3. 一度に一箇所だけを変更する
まず第一に、パフォーマンス問題は最初から再現が可能、もしくは少なくとも既知の許容差範囲のなかでは再現が可能と仮定します。もし問題が再現が可能でなければ実施したどのような変更の効果も測定することができません。そのため、戻って結果が再現可能となるような方法でワークロードやテストケースを構成します。パフォーマンス問題が再現が可能であることが確認できたのなら、変更が役立つかどうかを確認するために一度に一箇所のみを変更します。
時間の都合(特にダウンタイムや停止を必要最小限にしたい場合)によっては複数箇所の変更が必要になる場合があるかもしれません。そのような場合、同じエリアに影響を与えることがない複数箇所を変更して個別に評価します。例えば、単独のSQL文に影響するSQLプロファイルを実装とコネクションプーリングの挙動を制御する中間層の変更などです。
4. パフォーマンスチューニングはインタラクティブなプロセスである
パフォーマンスチューニングはインタラクティブなプロセスであることを忘れないでください。ひとはせっかちなのですぐに改善を望みます。しかし、いくつかの変更は役に立つかもしれませんが、ほかの変更は役に立たないかもしれないことに気付くでしょう。いくつかの場合、修正しているもののすぐ後ろにボトルネックがあるかもしれません。これは修正が役に立たなかったことを意味するわけではなく、単に更なる改善が必要だということを意味しています。データベース、OS、Exadataによって提供されるパフォーマンス統計の分析はボトルネックや改善すべきエリアがどこにあるかを決定するのに役立ちます。主要なアプリケーションのメトリックは単にパフォーマンス評価に役立つ全体の指標にすぎませんが、独立した統計はパフォーマンスチューニングの成果に集中するのに役立ちます。
これは最初の秘訣で説明したように事前に判定基準を定義することが重要な理由です。目標を達成したときに変更を継続するとかえって悪くなるリスクがあります。
5. パフォーマンスレポートとそれを利用するタイミングに詳しくなる。その範囲を考慮する
Oracleデータベースは多数のパフォーマンス統計やパフォーマンスレポートを提供しています。AWRレポートはもっとも一般的に利用されているパフォーマンス診断ツールで、AWRレポートには様々な種類があります(グローバル、シングルインスタンス、期間比較、グローバル期間比較、AWR SQLレポート、PDBレポート)。AWRレポートは問題が広範囲におよぶ場合には役立ちます。 もし問題がユーザーやクエリーのサブセットに影響しているのであれば、AWR SQLレポート、SQLモニターレポート、SQL詳細レポートなどが調査には非常に役立ちます。
ASHレポートはインスタンス/データベース全体のアクティブセッションの履歴、特定のユーザーやSQL文やセッションの他の視点に基づいたフィルター処理のどちらの場合でも使用できます。
AWRレポートにあるExadataのセクションではストレージセルによって管理されて収集されている統計、つまりインスタンスやデータベースに関係しないストレージセルでのアクティビティをみることができます。そのため、Exadataの統計の範囲は通常のAWRレポートの範囲より広いため、AWR PDBレポートやAWR SQLレポートには含まれません。
6. パフォーマンスデータのソースを理解する
パフォーマンスレポートはデータベースですぐに利用できるv$ビューとして知られている動的パフォーマンスビューを経由してパフォーマンスデータを要約します。ただし、データベースのビューとして公開される測定や統計は様々な種類があります:
測定/カウント − Exadataの情報も含んだAWRで公開されているほとんどのものを含んでいます。
派生(メトリック) − これらの統計は1秒ごとやトランザクションごとのレートを出すために測定/カウントの統計に基づいて派生または算出されていて、通常は(v$sysmetric、v$sysmetric_historyなどのような)v$metric* ビューで公開されています。
サンプリング − 例えば、ASHです。アクティブセッションは定期的にサンプリングされていてデータベース内部の時間をどのように消費しているかを判断するために使用できます。ASHは非常に便利なユーティリティーですが、サンプリングされているため、賢明に使う必要があります。具体的には、John BeresniewiczとGraham Woodによって広く紹介されている”Bad ASH Math”に注意してください。
Exadataでは、以下のような追加のデータソースもあります
ExaWatcher − これには(5秒ごとの)詳細なデータが含まれていて、OSの統計とセルサーバーの統計の両方を含んでいます。
セルのメトリック履歴 − これにはセルソフトウェアによって測定された累積と(秒ごと、リクエストごとの)派生の統計の両方を含んでいます。
7. Exadataでのパフォーマンスチューニングの手法は変更しない
DB時間を使用します。Exadataの統計がAWRレポートで公開されているとしても、Exadataの統計に飛び込む前にデータベースの待機イベントが反映されているI/Oの問題がないかを最初に確認します。
適切なデータベース設計の原則を実践し続けます。ほとんどの場合、ユーザーはExadataが提供するスマートな機能によって難を逃れていますが、適切なデータベース設計の原則を無視した適用事例をたくさんみました。ただし、適切なデータベース設計の原則に従っていれば、あなたはシステムから多くのものを得ることができます。例えば、Exadataで実行されているからといって、それはすべてスマートスキャンであることを意味しません。スキーマをレビューして、SQL文のアクセスパターンに基づいた適切なインデックスやパーティショニングとなっているか確認してください。
また、Exadataの高性能なストレージはストレージに関連しない問題の助けにはなりません。例えば、不十分なコネクション管理や繰り返されるパースは優れたストレージソリューションがあってもまだ発生するアプリケーションレベルの問題です。同じように、行ごとの処理(またはTom Kyteによる造語、”Row by row = slow by slow”)はまとめた処理に比較すると多大なオーバーヘッドがあるため、必ずしも優れたストレージソリューションによって改善されるわけではありません。
8. 悪いSQLは悪いSQLである
下手に記述されたSQL文は実行環境に関係なく、不十分に実行されます。コストベースオプティマイザーは記述されたSQLに最適な実行計画の探索を試みます。Exadataでは下手に記述されたSQL文を実行するとオフロード処理や高速I/Oの観点で向上するかもしれませんが、上手に記述されたSQL文と適切な実行計画と同じようにはなりません。
例えば、テーブルに複数回アクセスするSQL文を一度だけ実行できる場合、テーブルへのアクセス中に不要な追加処理が発生することになります。別の例では、実行するSQL文のフィルタリング述部で指定する代わりに、アプリケーションでのデータ出力のフィルタリングに依存しているアプリケーションです。そのような場合、アプリケーションでのデータのフィルタリングに依存するよりも、事前にデータベースによって処理されるデータセットを削減するほうがいいでしょう。アプリケーションへの依存は通常データベース内部での大きなデータセットの不必要な処理につながります。
9. データドリブンでの分析
しばしば、ユーザーが多数の利用可能なパフォーマンスデータをみることなく直感に基づいて問題がどこにあるのか推測して変更を実施するのを目にします。また、ユーザーは特に彼らが信じていることの発生を裏付けない利用可能なデータを無視することを選択します。代わりに、利用可能なデータをなぜパフォーマンスの問題が発生しているのかの仮設を立てるために利用し、それに基づいてチューニングの推奨を作成します。
10. 車輪の再発明はしないで、荷馬車を更新する
データベースが提供する新機能に常に把握しておき、いつものように物事を実施するのではなく、それらを賢明に利用してください。例えば、データベース19cのリアルタイム統計と自動インデックスでは、データベースが自動的にインデックスを設定して機械学習を用いて統計情報を維持できるため、統計情報の固定化、ストアドアウトラインなどの利用のような人手への依存を削減します。
同じように、もしOracleデータベースのためのExadataのようなベンダーによる最高クラスのソリューションを使う機会がある場合、それを使ってください!そのシステムはプロフェッショナルによって設計されていて、多くの推測作業を取り除いて、平凡なタスクの量を削減するため、より価値の高いプロジェクトとイノベーションにもっと価値を付加することに集中できます。
僕がAWRレポートを好きな理由(DBメモリ編)
この記事は、JPOUG Advent Calendar 2019の14日目の記事です。
13日目の記事は三原 健一さんの記事『負荷テストデータ作成に関するTips — 指定率行の抽出・更新 — | サイクル&オラクル』でした。
はじめに
Oracle DBAとして経験を積んでちょっとデキる感と自信を持てるようになるのは、やはりDBパフォーマンス・チューニングの領域に足を踏み入れてからだと思います。

私もインフラエンジニアとしてまだOracle DBを担当していなかったころは、DBのトラブルシューティングで呼ばれたエンジニアやコンサルの人たちがAWRレポートをふむふむと眺めてはボトルネック分析している姿をみてカッコいいなーと憧れていました。
DBパフォーマンス・チューニングは大きく分類すると
に分かれると思いますが、AWRレポートは主にインスタンス・チューニングで利用します。
この記事ではOracle DBのパフォーマンス・チューニングにおいて要となるAWRレポートが好きな理由を書きたいと思います(技術解説じゃないです)。
AWRの概要
AWRについて
Oracle DB 10gからOracle DBのチューニング方法としてDB Timeベース・チューニング ができるようになり、Oracle DBの稼働情報をスナップショットとして保存するAWR(Automatic Workload Repository)の機能が導入されました。Oracle 8iから導入されているStatspackの進化版の機能になります。
SGA(System Global Area)上にあるOracle DBの稼働情報をバックグラウンド・プロセスのMMON(Memory Monitor)が収集して定期的にSYSAUX表領域上のリポジトリにスナップショットとして記録します。記録されたスナップショットは一定期間保存されます(デフォルトでは60分間隔で8日間保存されます)。
また、AWRを利用するにはOracle DBのEnterprise EditionとDiagnostics Packオプションが必要になります。
AWRレポートについて
AWRレポートは任意の2時点で取得したスナップショット間の差分からOracle DBのパフォーマンス関連の統計をレポート形式で出力したものになります。
Oracle DBインスタンス全体のアクティビティ、アプリケーションの傾向、待機イベントの発生状況などの負荷状況を把握することができます。
定期的に正常稼働時のAWRレポートを取得しておいて、DBトラブル発生時のAWRレポートと負荷傾向などを比較分析するのが理想的ですが、DBトラブル発生時のAWRレポートだけでも分析はできます。

AWRレポートが好きな理由
私がAWRレポートを好きなのは基本的にパフォーマンス分析やトラブルシューティングが好きなのもありますが、Oracle DBは内部がブラックボックスなのにAWRレポートを分析するとOracle DBの内部でなにが起きているのかがいろいろ想像できるからです!
今回はそのなかでもDBメモリの分析について書きました〜
DBのメモリ状況がわかる!
基本的にOracle DBのアーキテクチャはメモリ上にアクセス頻度の高いデータを置くことによって、ディスクI/Oを減らして高速化を実現していますので、DBのメモリ状況はとても重要です。
AWRレポートからSGAやPGA(Program Global Area)のメモリの確保状況などを分析できます。
キャッシュヒット率とアドバイザリをみる
Report SummaryのInstance Efficiency Percentagesでバッファ・キャッシュとライブラリ・キャッシュのヒット率をみることができます。
システムの特性にもよりますが、OLTPの場合は95%以上が一般的です。

ヒット率が悪い場合、Buffer Pool Advisoryをみてサイズ拡張による物理ブロック読込時間の減少が顕著であれば必要なブロックがバッファ・キャッシュ上にキャッシュできずにI/O待機が発生している可能性がありますし、Shared Pool Advisoryをみてサイズ拡張によるロード時間の減少が顕著であれば必要なライブラリ・キャッシュ・オブジェクトがキャッシュアウトしている可能性がありますので、SGAの各コンポーネントのサイズ拡張を検討します(Size Factor 1.0が現在のサイズ)。


各メモリ・コンポーネントの状況をみる
Memory StatisticsのMemory Dynamic Componentsで各メモリ・コンポーネントの状況をみることができます。
自動メモリ管理(AMM)や自動共有メモリ管理(ASMM)を使用しているときにSGAの各メモリ・コンポーネントでメモリ不足が発生した場合には、バッファ・キャッシュとの間で自動的にサイズ調整されます。
各メモリ・コンポーネントのサイズ調整には定期取得した統計情報に基づいて行われる場合(DEFERREDモード)とメモリ割当てエラー(ORA-04031)の発生を回避するために緊急で行われる場合(IMMEDIATEモード)がありますが、IMMEDIATEモードでのサイズ調整が発生している場合には当該メモリ・コンポーネントのサイジングが適切でない可能性が高いです(IMMがIMMEDIATEモード)。

REDOログ・バッファのリトライ状況をみる
SQLによる更新処理が発生するとREDO ログを生成とともにREDOログ・バッファに領域を確保して配置しますが、REDOログ・バッファはSGAのメモリ・コンポーネントのなかでもAMMやASMMによる自動サイズ調整の対象外のため、REDOログ・バッファのサイズが小さい場合には領域を確保できずにリトライ処理が発生する場合があります。 REDOログ・バッファの領域が確保できないと更新処理を開始できないため、リトライ処理が多く発生していると更新処理が性能劣化する要因となります。
REDOログ・バッファの領域確保のリトライ処理が発生しているかどうかは、Instance Activity StatisticsのOther Instance Activity Statsでredo buffer allocation retriesで確認することができます。
また、REDOログ・バッファのサイズが小さくて領域が確保できない場合だけではなく、I/O性能の問題でバックグラウンド・プロセスのLGWR(Log Writer)によるオンラインREDOログ・ファイルのスイッチに時間を要している場合などにもリトライ処理は発生しますので、Wait Events StatisticsのForeground Wait Eventsでlog file switch *の待機イベントの発生回数を確認してREDOログ・バッファの領域不足の可能性が高ければ拡張を検討します。

PGAのサイズをみる
すべてのサーバ・プロセスで使用するPGA サイズの合計(総PGAサイズ)がpga_aggregate_target(初期化パラメータ) で設定したターゲット値に近づくと1 SQL 作業領域の確保可能なサイズを減少させることで PGA サイズの合計がターゲット値を超えないように自動調整されます。
1 SQL 作業領域毎の確保サイズが減少するとソート処理やハッシュ結合を実施する場合に処理に必要な PGA メモリが確保できなくなるため、一時表領域への読み書きによる I/O 増加で処理時間が大きく増加する可能性があります。
各処理で適切な PGA メモリが確保できているかどうかは、Advisory StatisticsのPGA Aggr Target StatsでPGA サイズの合計がターゲット値に近づいていないことや1 SQL 作業領域の確保可能サイズが減少していないこと、

PGA Aggr Target Histogramでマルチ・パスが大量に発生していないことを確認することなどで判断します。

適切なPGAメモリが確保できていない可能性が高い場合には、pga_aggregate_targetの拡張を検討します。